
A Billion Users A Day: A Deep Dive Into Modern Distributed Systems


This article is an extract from a talk I've done earlier this year for GeeksBlala. You can check out the talk here – if you speak Moroccan Arabic :):
Introduction
In today’s digital age, we interact with distributed systems constantly, often without even realizing it. From social media platforms to online banking, these systems power many of the services we rely on. But what exactly are distributed systems, and how do they manage to operate at such a massive scale? This article delves into the intricacies of modern distributed systems, exploring their models, challenges, and the ingenious solutions that make them tick.
Models of Distributed Systems
A distributed system is a collection of interconnected computers that work together to achieve a common goal. These systems can be modeled in various ways, depending on the specific questions we want to answer. For instance, we might model a distributed system as a set of processes communicating through message queues, or as a network of servers responding to remote procedure calls. The choice of model depends on the level of abstraction and the aspects of the system we want to emphasize.
A coordination problem
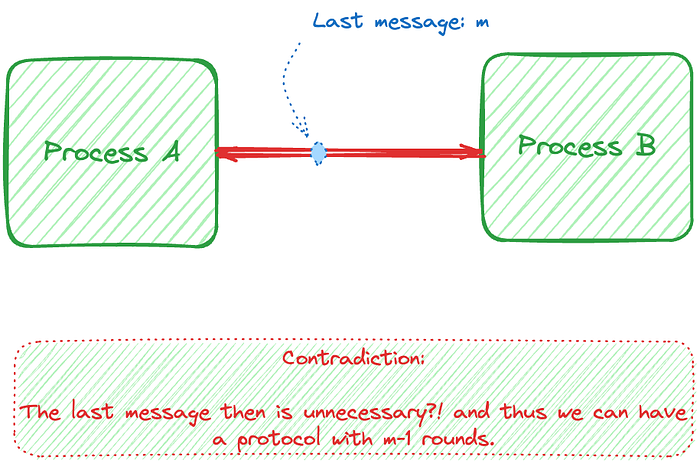
Imagine the following system:
“ Two processes, A and B, communicate by sending and receiving messages on a bidirectional channel. Neither process can fail. However, the channel can experience transient failures, resulting in the loss of a subset of the messages that have been sent. Devise a protocol where either of two actions α and β are possible, but (i) both processes take the same action and (ii) neither takes both actions.”
For the purpose of this problem:
- m: number of rounds
- Last message is sent by A
- A, B: processes sending messages
- Q, R: actions to be taken

Is it possible for a protocol, that solves the problem in the minimum number of rounds, to exist?
The reasoning goes as follows:
1. Since A would not receive any confirmation, the action A takes will not depend on that last message
2. A’s choice of using action Q or R will not depend on m
3. If the mth message is lost B has to still make a choice between Q and R and thus, the action B takes will no depend on that last message
4. B’s choice of using action Q and R will not depend on m
Time, Clocks, and the Ordering of Events
One of the fundamental challenges in distributed systems is understanding and managing time. Unlike a single computer, where events happen in a strict sequential order, a distributed system has no global clock. This means that events on different machines can only be partially ordered, leading to potential ambiguity when determining the order in which events occurred.
To address this, distributed systems employ logical clocks, which assign timestamps to events without relying on physical clocks. By following specific rules, these logical clocks help establish a total ordering of events, ensuring that all machines agree on the sequence in which events happened.
Partial Ordering
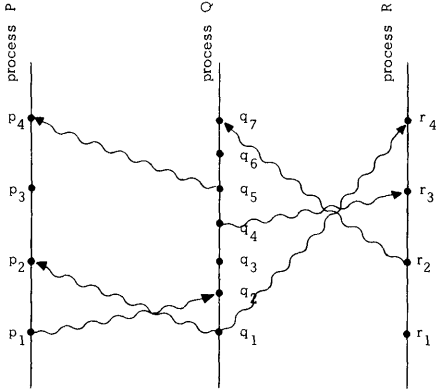
Partial ordering relies on the following three fundamental concepts:
- Logical Timestamps: Each event is assigned a logical timestamp. This timestamp is not a precise measure of time but rather a way to order events within a system.
- Lamport Timestamps: A simple approach where each process maintains a logical clock. Whenever an event occurs, the clock is incremented. Messages carry their sender’s clock value.
- Vector Clocks: Each process maintains a vector of timestamps, one for each process in the system. When an event occurs, the process increments its own timestamp in the vector. Messages carry the sender’s entire vector.
2. Happens-Before Relationship: A relation “happens-before” is defined between events:
- If A and B are events in the same process, and A occurs before B, then A happens-before B.
- If A is the sending of a message and B is the receipt of that message, then A happens-before B.
- If A happens-before B and B happens-before C, then A happens-before C.
3. Partial Order: The “happens-before” relation defines a partial order on the events in the system. This means that some events may not be comparable, but for those that are comparable, a clear ordering exists.
Let’s consider for example two processes, P1 and P2.
- P1 sends a message to P2.
- P2 receives the message and sends a reply to P1.
- P1 receives the reply.
Using logical timestamps, we can establish a partial order:
- P1’s send event happens-before P2’s receive event.
- P2’s receive event happens-before P2’s send event.
- P2’s send event happens-before P1’s receive event.
Therefore, the events can be partially ordered as follows:
- P1’s send event < P2’s receive event < P2’s send event < P1’s receive event.
Logical clocks & total ordering
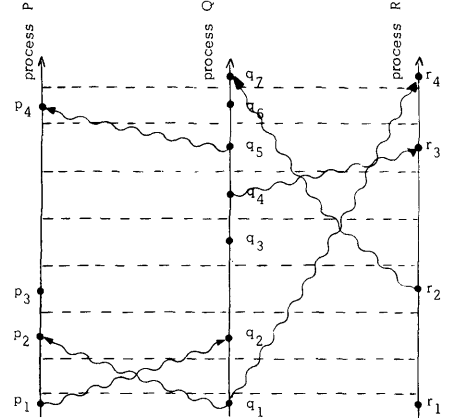
Two rules are needed to be maintained to transition from a partial ordering to total ordering:
- IR1. Each process P~ increments Ci between any two successive events.
- IR2. (a) If event a is the sending of a message m by process P~, then the message m contains a timestamp Tm= Ci(a). (b) Upon receiving a message m, process Pi sets Ci greater than or equal to its present value and greater than Tin.

Consensus, Replication & Fault-tolerance
Another critical challenge in distributed systems is achieving consensus, which means getting all machines to agree on a single value or course of action. This is crucial for tasks like replicating data, where multiple copies of data must be kept consistent across different machines.
However, achieving consensus in an asynchronous distributed system, where there’s no guarantee on the timing of messages, is impossible if even a single machine fails. This fundamental limitation, known as the FLP impossibility result, highlights the challenges in designing robust distributed systems.
FLP Theorem. No consensus protocol is totally correct in spite of one fault.
Despite this challenge, practical solutions like chain replication have been developed to provide high throughput and availability while maintaining strong consistency guarantees. In chain replication, servers are organized in a linear chain, with updates processed at the head and queries at the tail, ensuring a consistent order of operations.
Chain Replication for Supporting High Throughput and Availability
In chain replication, the servers replicating a given object objID are linearly ordered to form a chain. The first server in the chain is called the head, the last server is called the tail.
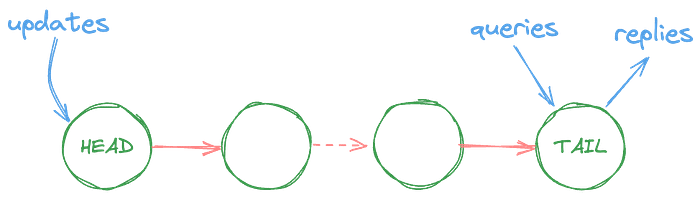
The following algorithm details how the chain is managed:
State is:
HistobjID : update request sequence
PendingobjID : request set
Transitions are:
T1: Client request r arrives:
PendingobjID := PendingobjID ∪ {r}
T2: Client request r ∈ PendingobjID ignored:
PendingobjID := PendingobjID − {r}
T3: Client request r ∈ PendingobjID processed:
PendingobjID := PendingobjID − {r}
if r = query(objId, opts ) then
reply according options opts based on HistobjID
else if r = update(objId, newVal, opts) then
HistobjID := HistobjID · r
reply according options opts based on HistobjIDReply Generation.
The reply for every request is generated and sent by the tail.
Query Processing.
Each query request is directed to the tail of the chain and processed there atomically using the replica of objID stored at the tail.
Update Processing.
Each update request is directed to the head of the chain. The request is processed there atomically using replica of objID at the head, then state changes are forwarded along a reliable FIFO link to the next element of the chain (where it is handled and forwarded), and so on until the request is handled by the tail.
Failure of intermediate servers.
Failure of a server S internal to the chain is handled by deleting S from the chain.
Failure of the head.
Deleting server H from the chain has the effect of removing from PendingobjID those requests received by H but not yet forwarded to a successor. Removing a request from PendingobjID is consistent with transition T2 (ignored).
Failure of the tail.
Update Propagation Invariant: For servers labeled i and j such that i ≤ j holds (i.e., i is a predecessor of j in the chain) then: Hist j objID <= Hist i objID .

Paxos And Friends
Paxos is a widely used consensus algorithm that provides a fault-tolerant way for a distributed system to agree on a single value. It works by assigning different roles to machines, such as proposers, acceptors, and learners, and using a series of message exchanges to reach a consensus.
Paxos is designed to be fault-tolerant, meaning it can continue to operate even if some nodes fail or network partitions occur. It also ensures that only one value is eventually agreed upon, preventing inconsistencies in the distributed system.
Spanner, a globally distributed database developed by Google, uses Paxos to maintain data consistency across its vast network of servers. It combines Paxos with innovative techniques like TrueTime, a globally synchronized clock, to provide high availability and scalability without compromising consistency.
Consensus algorithm
We let the three roles in the consensus algorithm be performed by three classes of agents: proposers, acceptors, and learners.
Here’s a simplified overview:
- Proposal: A node proposes a value.
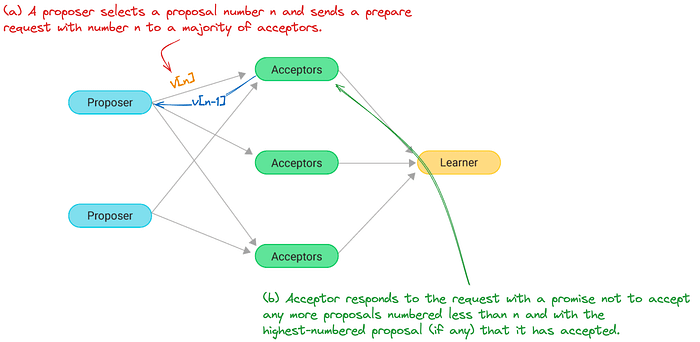
- Prepare: The proposer sends a prepare message to a quorum of nodes.
- Promise: If a node hasn’t promised another value, it sends a promise to the proposer.
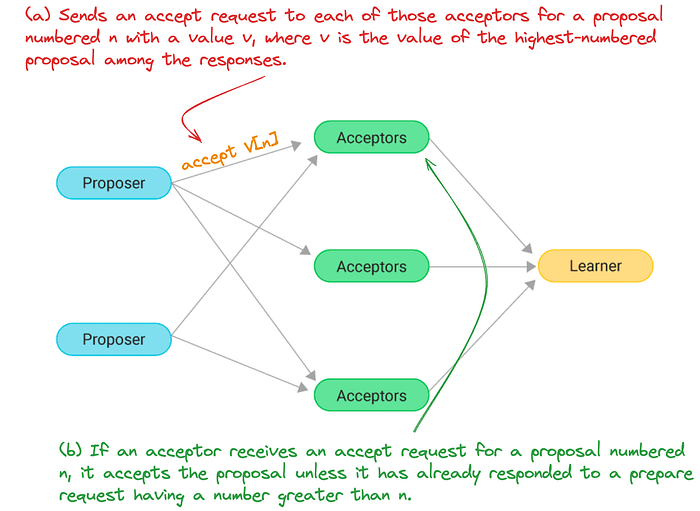
- Accept: The proposer sends an accept message to a quorum of nodes, including the value it proposed.
- Accept: If a node hasn’t accepted another value, it accepts the proposed value.
- Commit: Once a value has been accepted by a quorum, it is considered committed.
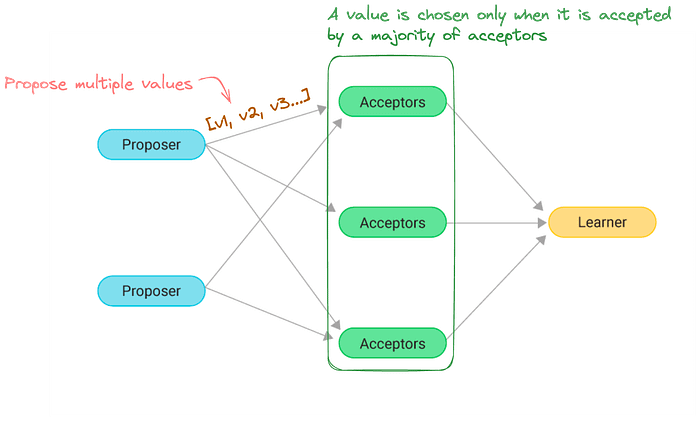
We can split the whole inner working into two main steps:
Phase I: prepare
Phase II: accept
The Future of Distributed Systems
The field of distributed systems is constantly evolving, with edge computing and blockchain emerging as two significant trends. Edge computing brings computation closer to the data source, while blockchain offers a decentralized and secure method for recording transactions. The potential synergy between these two technologies holds promise for the future of large-scale systems, but it remains to be seen how they can be effectively merged and utilized to their full potential.